Implementing the Service Worker Cache API in Gecko
For the last few months I’ve been heads down, implementing the Service Worker Cache API in gecko. All the work to this point has been done on a project branch, but the code is finally reaching a point where it can land in mozilla-central. Before this can happen, of course, it needs to be peer reviewed. Unfortunately this patch is going to be large and complex. To ease the pain for the reviewer I thought it would be helpful to provide a high-level description of how things are put together.
If you are unfamiliar with Service Workers and its Cache API, I highly recommend reading the following excellent sources:
- The Offline Cookbook by Jake Archibald
- Introduction to Service Worker by Matt Gaunt
- Using Service Workers on MDN
- Service Worker Spec
- Fetch Spec
Building Blocks
The Cache API is implemented in C++ based on the following Gecko primitives:
-
WebIDL DOM Binding
All new DOM objects in gecko now use our new WebIDL bindings.
-
PBackground IPC
PBackground is an IPC facility that connects a child actor to a parent actor. The parent actor is always in the parent process. PBackground, however, allows the child actor to exist in either a remote child content process or within the same parent process. This allows us to build services that support both electrolysis (e10s) and our more traditional single process model.
Another advantage of PBackground is that the IPC calls are handled by a worker thread rather than the parent process main thread. This helps avoid stalls due to other main thread work.
-
Quota Manager
Quota Manager is responsible for managing the disk space used by web content. It determines when quota limits have been reached and will automatically delete old data when necessary.
-
SQLite
mozStorage is an API that provides access to an SQLite database.
-
File System
Finally, the Cache uses raw files in the file system.
Alternatives
We did consider a couple alternatives to implementing a new storage engine for Cache. Mainly, we thought about using the existing HTTP cache or building on top of IndexedDB. For various reasons, however, we chose to build something new using these primitives instead. Ultimately it came down to the Cache spec not quite lining up with these solutions.
For example, the HTTP cache has an optimization where it only stores a single response for a given URL. In contrast, the Cache API spec requires that multiple Responses can be stored per-URL based on VARY headers, multiple Cache objects, etc. In addition, the HTTP cache doesn’t use the quota management system and Cache must use the quota system.
IndexedDB, on the other hand, is based on structured cloning which doesn’t currently support streaming data. Given that Responses could be quite large and come in from the network slowly, we thought streaming was a priority to reduce the amount of required memory.
Also, while not a technical issue, IndexedDB was undergoing a significant rewrite at the time the Cache work began. We felt that this would delay the Cache implementation.
10,000-Foot View
With those primitives in mind, the overall structure of the Cache implementation looks like this:
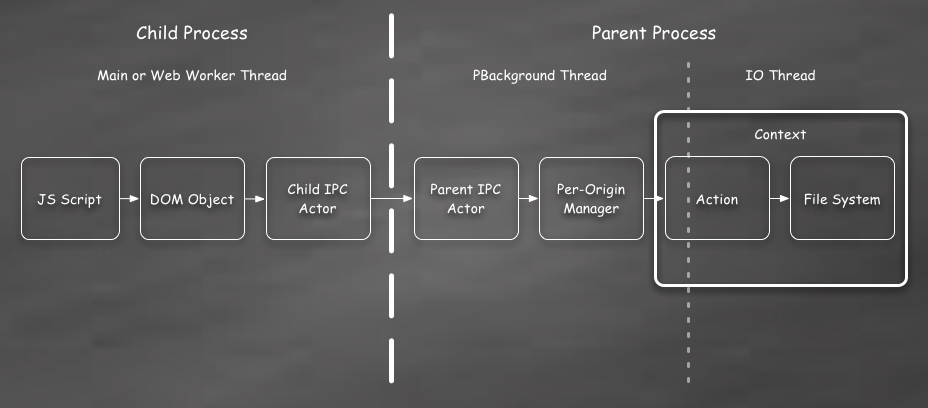
Here we see from left-to-right:
-
JS Script
Web content running in a JavaScript context on the far left. This could be in a Service Worker, a normal Web Worker, or on the main thread.
-
DOM Object
The script calls into the C++ DOM object using the WebIDL bindings. This layer does some argument validation and conversion, but is mostly just a pass through to the other layers. Since most of the Cache API is asynchronous the DOM object also returns a Promise. A unique RequestId is passed through to the Cache backend and is later used to find the Promise on completion.
-
Child and Parent IPC Actors
The connection between the processes is represented by a child and a parent actor. These have a one-to-one correlation. In the Cache API request messages are sent from the child-to-parent and response messages are sent back from the parent-to-child. All of these messages are asynchronous and non-blocking.
-
Manager
This is where things start to get a bit more interesting. The Cache spec requires each origin to get its own, unique CacheStorage instance. This is accomplished by creating a separate per-origin Manager object. These Manager objects can come and go as DOM objects are used and then garbage collected, but there is only ever one Manager for each origin.
-
Context
When a Manager has a disk operation to perform it first needs to take a number of stateful steps to configure the QuotaManager properly. All of this logic is wrapped up in what is called the Context. I’ll go into more detail on this later, but suffice it to say that the Context handles handles setting up the QuotaManager and then scheduling Actions to occur at the right time.
-
Action
An Action is essentially a command object that performs a set of IO operations within a Context and then asynchronously calls back to the Manager when they are complete. There are many different Action objects, but in general you can think of each Cache method, like
match()orput(), having its own Action. -
File System
Finally, the Action objects access the file system through the SQLite database, file streams, or the nsIFile interface.
Closer Look
Lets take a closer look at some of the more interesting parts of the system. Most of the action takes place in the Manager and Context, so lets start there.
Manager
As I mentioned above, the Cache spec indicates each origin should have its own
isolated caches object. This maps to a single Manager instance for all
CacheStorage and Cache objects for scripts running in the same origin:
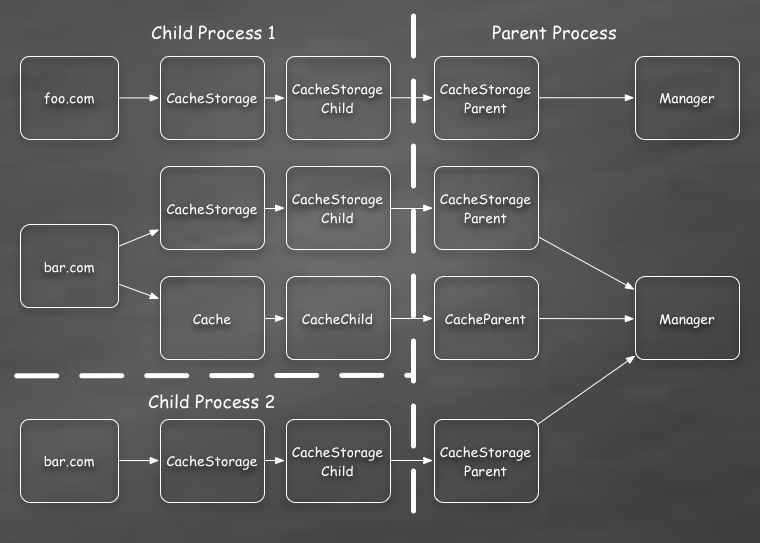
Its important that all operations for a single origin are routed through the same Manager because operations in different script contexts can interact with one another.
For example, lets consider the following CacheStorage method calls being executed by scripts running in two separate child processes.
- Process 1 calls
caches.open('foo'). - Process 1’s promise resolves with a Cache object.
- Process 2 calls
caches.delete('foo').
At this point process 1 has a Cache object that has been removed from the
caches CacheStorage index. Any additional calls to caches.open('foo')
will create a new Cache object.
But how should the Cache returned to Process 1 behave? It’s a bit poorly
defined in the spec, but the current interpretation is that it should behave
normally. The script in process 1 should continue to be able to access
data in the Cache using match(). In addition, it should be able to store
A value using put(), although this is somewhat pointless if the Cache is
not in caches anymore. In the future, a caches.put() call may be added
to let a Cache object to be re-inserted into the CacheStorage.
In any case, the key here is that the caches.delete() call in process 2
must understand that a Cache object is in use. It cannot simply delete all
the data for the Cache. Instead we must reference count all uses of the
Cache and only remove the data when they are all released.
The Manager is the central place where all of this reference tracking is implemented and these races are resolved.
A similar issue can happen with cache.match(req) and cache.delete(req). If
the matched Response is still referenced, then the body data file needs to
remain available for reading. Again, the Manager handles this by tracking
outstanding references to open body files. This is actually implemented by using
an additional actor called a StreamControl which will be shown in the
cache.match() trace below.
Context
There are a number of stateful rules that must be followed in order to use the QuotaManager. The Context is designed to implement these rules in a way that hides the complexity from the rest of the Cache as much as possible.
Roughly the rules are:
- First, we must extract various information from the
nsIPrincipalby callingQuotaManager::GetInfoFromPrincipal()on the main thread. - Next, the Cache must call
QuotaManager::WaitForOpenAllowed()on the main thread. A callback is provided so that we can be notified when the open is permitted. This callback occurs on the main thread. - Once we receive the callback we must next call
QuotaManager::EnsureOriginIsInitialized()on the QuotaManager IO thread. This returns a pointer to the origin-specific directory in which we should store all our files. - The Cache code is now free to interact with the file system in the directory
retrieved in the last step. These file IO operations can take place on any
thread. There are some small caveats about using QuotaManager specific APIs
for SQLite and file streams, but for the most part these simply require
providing information from the
GetInfoFromPrincipal()call. - Once all file operations are complete we must call
QuotaManager::AllowNextSynchronizedOp()on the main thread. All file streams and SQLite database connections must be closed before making this call.
The Context object functions like a reference counted RAII-style object. It
automatically executes steps 1 to 3 when constructed. When the Context object’s
reference count drops to zero, its destructor runs and it schedules the
AllowNextSynchronzedOp() to run on the main thread.
Note, while it appears the GetInfoFromPrincipal() call in step 1 could be
performed once and cached, we actually can’t do that. Part of extracting
the information is querying the current permissions for the principal. Its
possible these can change over time.
In theory, we could perform the EnsureOriginIsInitialized() call in step 3 only
once if we also implemented the nsIOfflineStorage interface. This interface
would allow the QuotaManager to tell us to shutdown when the origin directory
needs to be deleted.
Currently the Cache does not do this, however, because the nsIOfflineStorage
interface is expected to change significantly in the near future. Instead, Cache
simply calls the EnsureOriginIsInitialized() method each time to re-create the
directory if necessary. Once the API stabilizes the Cache will be updated to
receive all such notifications from QuotaManager.
An additional consequence of not getting the nsIOfflineStorage callbacks is
that the Cache must proactively call QuotaManager::AllowNextSynchronizedOp()
so that the next QuotaManager client for the origin can do work.
Given the RAII-style life cycle, this is easily achieved by simply having the Action objects hold a reference to the Context until they complete. The Manager has a raw pointer to the Context that is cleared when it destructs. If there is no more work to be done, the Context is released and step 5 is performed.
Once the new nsIOfflineStorage API callbacks are implemented the Cache will
be able to keep the Context open longer. Again, this is relatively easy and
simply needs the Manager to hold a strong reference to the Context.
Streams and IPC
Since mobile platforms are a key target for Service Workers, the Cache API needs to be memory efficient. RAM is often the most constraining resource on these devices. To that end, our implementation should use streaming whenever possible to avoid holding large buffers in memory.
In gecko this is essentially implemented by a collection of classes that
implement the nsIInputStream interface. These streams are pretty
straightforward to use in normal code, but what happens when we need to serialize
a stream across IPC?
The answer depends on the type of stream being serialized. We have a couple existing solutions:
- Streams created for a flat memory buffer are simply copied across.
- Streams backed by a file have their file descriptor
dup()‘d and passed across. This allows the other process to read the file directly without any immediate memory impact.
Unfortunately, we do not have a way to serialize an nsIPipe across IPC without
completely buffering it first. This is important for Cache, because this is the
type of stream we receive from a fetch() Response object.
To solve this, Kyle Huey is implementing a new CrossProcessPipe that will send the data across the IPC boundary in chunks.
In this particular case we will be sending all the fetched
Response data from the parent-to-child when the fetch() is performed. If the
Response is passed to Cache.put(), then the data is copied back to the parent.
You may be asking, “why do you need to send the fetch() data from the child to
the parent process when doing a cache.put()? Surely the parent process
already has this data somewhere.”
Unfortunately, this is necessary to avoid buffering potentially large Response
bodies in the parent. It’s imperative that the parent process never runs out of
memory. One day we may be able to open the file descriptor in the parent,
dup() it to the child, and then write the data directly from the child process,
but currently this is not possible with the current Quota Manager.
Disk Schema
Finally, that brings us to a discussion of how the data is actually stored on disk. It basically breaks down like this:
- Body data for both Requests and Responses are stored directly in individual snappy compressed files.
- All other Request and Response data are stored in SQLite.
I know some people discourage using SQLite, but I chose it for a few reasons:
- SQLite provides transactional behavior.
- SQLite is a well-tested system with known caveats and performance characteristics.
- SQL provides a flexible query engine to implement and fine tune the Cache matching algorithm.
In this case I don’t think serializing all of the Cache metadata into a flat file, as suggested by that wiki page, would be a good solution here. In general, only a small subset of the data will be read or write on each operation. In addition, we don’t want to require reading the entire dataset into memory. Also, for expected Cache usage, the data should typically be read-mostly with fewer writes over time. Data will not be continuously appended to the database. For these reasons I’ve chosen to go with SQLite while understanding the risks and pitfalls.
I plan to mitigate fragmentation by performing regular maintenance. Whenever a row is deleted from or inserted into a table a counter will be updated in a flat file. When the Context opens it will examine this counter and perform a VACUUM if it’s larger than a configured constant. The constant will of course have to be fine-tuned based on real world measurements.
Simple marker files will also be used to note when a Context is open. If the
browser is killed with a Context open, then a scrubbing process will be
triggered the next time that origin accesses caches. This will look for
orphaned Cache and body data files.
Finally, the bulk of the SQLite specific code is isolated in two classes;
DBAction.cpp and DBSchema.cpp. If we find SQLite is not performant
enough, it should be straightforward to replace these files with another
solution.
Detailed Trace
Now that we have the lay of the land, lets trace what happens in the Cache when you do something like this:
// photo by leg0fenris: https://www.flickr.com/photos/legofenris/
var troopers = 'blob:https://mdn.github.io/6d4a4e7e-0b37-c342-81b6-c031a4b9082c'
var legoBox;
Promise.all([
fetch(troopers),
caches.open('legos')
]).then(function(results) {
var response = results[0];
legoBox = results[1];
return legoBox.put(troopers, response);
}).then(function() {
return legoBox.match(troopers);
}).then(function(response) {
// invade rebel base
});
While it might seem the first Cache operation is caches.open(), we actually
need to trace what happens when caches is touched. When the caches
attribute is first accessed on the global we create the CacheStorage DOM object
and IPC actors.
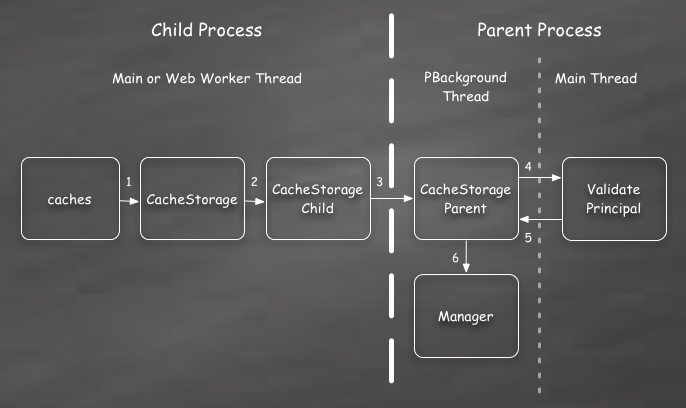
I’ve numbered each step in order to show the sequence of events. These steps are roughly:
- The global WebIDL binding for
cachescreates a new CacheStorage object and returns it immediately to the script. - Asynchronously, the CacheStorage object creates a new child IPC actor. Since this may not complete immediately, any requests coming in will be queued until actor is ready. Of course, since all the operations use Promises, this queuing is transparent to the content script.
- The child actor in turn sends a message to the parent process to create a corresponding parent actor. This message includes the nsIPrincipal describing the content script’s origin and other identifying information.
- Before permitting any actual work to take place, the principal provided to the actor must be verified. For various reasons this can only be done on the main thread. So an asynchronous operation is triggered to examine the principal and any CacheStorage operations coming in are queued.
- Once the principal is verified we return to the PBackground worker thread.
- Assuming verification succeeded, then the origin’s Manager can now be accessed or created. (This is actually deferred until the first operation, though.) Any pending CacheStorage operations are immediately executed.
Now that we have the caches object we can get on with the open(). This
sequence of steps is more complex:
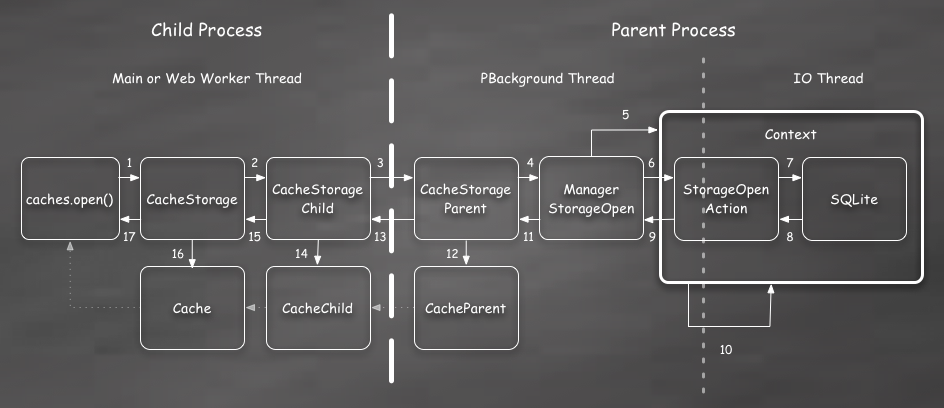
There are a lot more steps here. To avoid making this blog post any more boring than necessary, I’ll focus on just the interesting ones.
As with the creation trace above, steps 1 to 4 are basically just passing
the open() arguments across to the Manager. Your basic digital plumbing at
work.
Steps 5 and 6 make sure the Context exists and schedules an Action to run on the IO thread.
Next, in step 7, the Action will perform the actual work involved. It must find the Cache if it already exists or create a new Cache. This basically involves reading and writing an entry in the SQLite database. The result is a unique CacheId.
Steps 8 to 11 essentially just return the CacheId back to the actor layer.
If this was the last Action, then the Context is released in step 10.
At this point we need to create a new parent actor for the CacheId. This Cache actor will be passed back to the child process where it gets a child actor. Finally a Cache DOM object is constructed and used to resolve the Promise returned to the JS script in first step. All of this occurs in steps 12 to 17.
On the off chance you’re still reading this section, the script next performs
a put() on the cache:
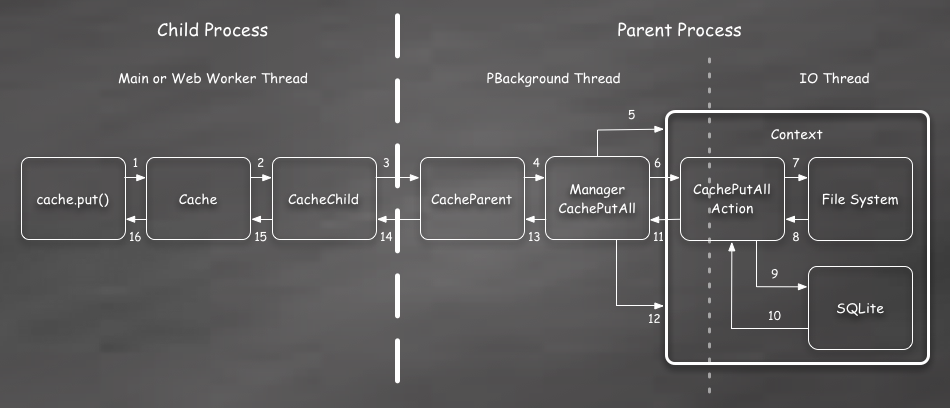
This trace looks similar to the last one, with the main difference occurring in the Action on the right. While this is true, its important to note that the IPC serialization in this case includes a data stream for the Response body. So we might be creating a CrossProcessPipe actor to copy data across in chunks.
With that in mind the Action needs to do the following:
- Stream body data to files on disk. This happens asynchronously on the IO thread. The Action and the Context are kept alive this entire time.
- Update the SQLite database to reflect the new Request/Response pair with a file name pointer to the body.
All of the steps back to the child process are essentially just there to indicate
completion. The put() operation resolves undefined in the success case.
Finally the script can use match() to read the data back out of the Cache:
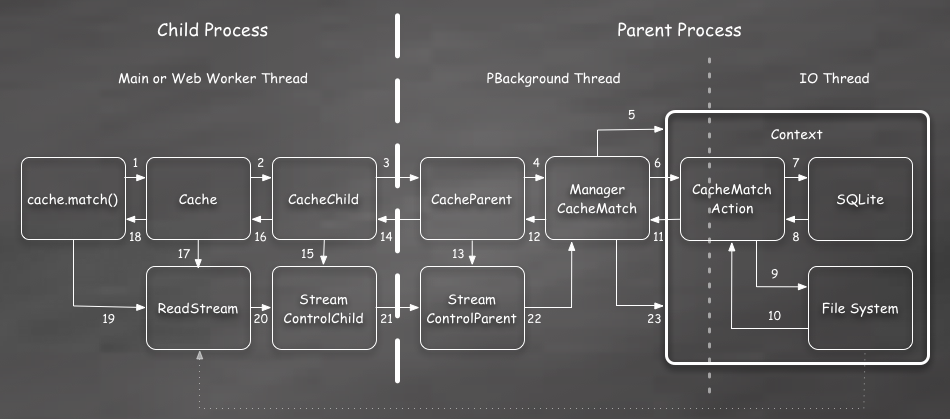
In this trace the Action must first query the SQLite tables to determine if the Request exists in the Cache. If it does, then it opens a stream to the body file.
Its important to note, again, that this is just opening a stream. The Action is only accessing the file system directory structure and opening a file descriptor to the body. Its not actually reading any of the data for the body yet.
Once the matched Response data and body file stream are passed back to the parent actor, we must create an extra actor for the stream. This actor is then passed back to the child process and used to create a ReadStream.
A ReadStream is a wrapper around the body file stream. This wrapper will send a message back to the parent whenever the stream is closed. In addition, it allows the Manager to signal the stream that a shutdown is occurring and the stream should be immediately closed.
This extra call back to the parent process on close is necessary to allow the Manager to reference track open streams and hold the Context open until all the streams are closed.
The body file stream itself is serialized back to the child process by dup()’in the file descriptor opened by the Action.
Ultimately the body file data is read from the stream when the content script
calls Response.text() or one of the other body consumption methods.
TODO
Of course, there is still a lot to do. While we are going to try to land the current implementation on mozilla-central, a number of issues will need to be resolved in the near future.
- SQLite maintenance must be implemented. As I mentioned above, I have a plan for how this will work, but it has not been written yet.
- Stress testing must be performed to fine tune the SQLite schema and configuration.
- Files should be de-duplicated within a single origin’s CacheStorage. This will be important for efficiently supporting some expected uses of the Cache API. (De-duplication beyond the same origin will require expanded support from the QuotaManager and is unlikely to occur in the near future.)
- Request and Response
clone()must be improved. Currently aclone()call results in the body data being copied. In general we should be able to avoid almost all copying here, but it will require some work. See bug 1100398 for more details. - Telemetry should be added so that we can understand how the Cache is being used. This will be important for improving the performance of the Cache over time.
Conclusion
While the Cache implementation is sure to change, this is where we are today. We want to get Cache and the other Service Worker bits off of our project branch and into mozilla-central as soon as possible so other people can start testing with them. Reviewing the Cache implementation is an important step in that process.
If you would like to follow along please see bug 940273. As always, feedback is welcome by email or on twitter.