Evaluating the Streams API's Asynchronous Read Function
For a while now Google’s Domenic Denicola, Takeshi Yoshino, and others have been working on a new specification for streaming data in the browser. The Streams API is important because it allows large resources to be processed in a memory efficient way. Currently, browser APIs like XMLHttpRequest do not support this kind of processing.
Mozilla is very interested in implementing some kind of streaming data interface. To that end we’ve been evaluating the proposed Streams spec to determine if its the right way forward for Firefox.
In particular, we had a concern about how the proposed read() function was
defined to always be asynchronous and return a promise. Given how often data
is read() from a stream, it seemed like this might introduce excessive overhead
that could not be easily optimized away. To try to address that concern we wrote
some rough benchmarks to see how the spec might perform.
TL;DR: The benchmarks suggest that the Streams API’s asynchronous
read() will not cause performance problems in practice.
The Concern
Before we describe the benchmarks, let’s discuss what our concern was in a more detail.
The spec currently defines the read() function as returning a promise. When
data is available in the stream, then the promise resolves with the data.
So a typical read loop might look like this with the proposed spec:
var reader = stream.getReader();
reader.read().then(function handleChunk(result) {
if (result.done) {
return;
}
processChunk(result.value);
return reader.read().then(handleChunk);
});
This API was ultimately chosen after much discussion in order to support certain optimizations.
In contrast, other streaming APIs often provide a synchronous read operation with some way to determine when data is available.
Consider what a read loop using node.js streams looks like:
stream.on('readable', function handleReadable() {
var chunk = stream.read();
while (chunk) {
processChunk(chunk);
chunk = stream.read();
}
stream.on('readable', handleReadable);
});
These loops have a lot in common. They both use an async callback to iteratively process chunks of data. The difference, however, is in how much work they can perform for each async callback.
The node.js streams can completely drain the stream on each async callback. In the Streams API loop, however, there is one async callback per chunk even if there are many chunks already buffered up in memory. In addition, it allocates an additional object each read for the promise.
We were concerned that these additional async callbacks and promise allocations would introduce a noticeable performance penalty.
In order to try to assess if this possibility we wrote a couple benchmarks. These benchmarks are not perfect. The spec is essentially conceptual at this point without a full concrete implementation. In addition, we want to compare to possible implementations. This is difficult to do without fully implementing the spec. Therefore, these benchmarks are very much speculative and may not reflect the final performance. Currently, however, they are the best that we have available.
Micro-Benchmarking
The first benchmark we tried was a micro test. It essentially executed the loops above for different numbers of “buffered chunks”. A version of benchmark.js was then used to repeat the tests and get stable, significant results.
In addition, the micro benchmark was executed using both native and Bluebird promises across a variety platforms and browsers.
The code for the micro benchmark is available on Github. You can also run the micro benchmark yourself.
So, what kind of results did this benchmark produce? First, lets compare native promises to Bluebird promises.
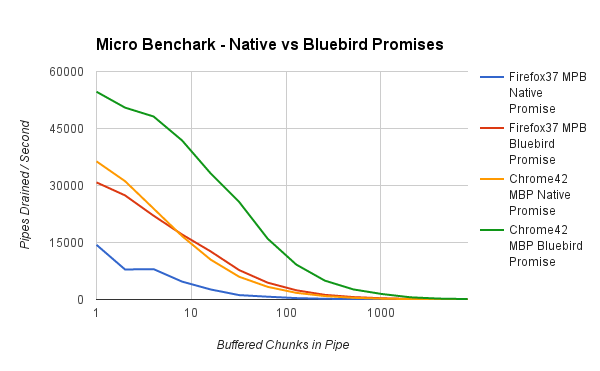
Here we can see that Bluebird promises are currently significantly faster than native promises in this test. This is not terribly surprising as there are known areas for improvement in both Firefox’s and Chrome’s promise implementations. In the long term, though, we expect both browsers’ native promises to be competitive with Bluebird performance.
Based on these results, we’ll just focus on the Bluebird results from now on.
With that in mind, lets see how things look on a desktop platform.
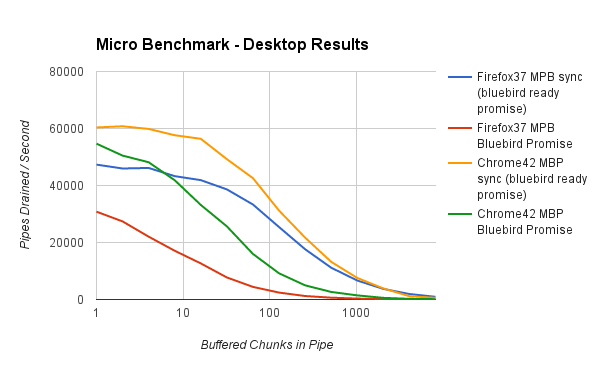
This shows that on both Chrome and Firefox the synchronous read loop achieves greater throughput than the async read loop. In addition, the sync read loop has a shallower slope and does not degrade as quickly as we increase the number of buffered chunks in the pipe.
Now lets look at performance on a Nexus5.
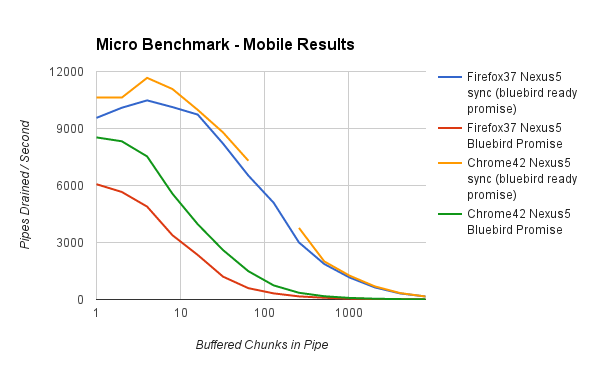
This shows a similar story, although the throughput is greatly reduced (as we would expect for a such a device). The drop off for the async read is significant enough that at 128 chunks in the pipe both Chrome and Firefox require more than 1ms to drain a pipe with the async read. Given 60fps time budgets, this is a significant amount of time.
At this point I’m sure some of you are saying “wait a minute, I thought the TLDR was that the async read was not a problem!” These results certainly do look grim.
Domenic, however, correctly pointed out that streams performance will typically be dominated by source or sink I/O. The micro benchmark does not capture the overall performance of a system using streams. What we really care about is how streams will perform in real systems and not in artificial benchmarks like this.
Approximating a System
So next we attempted to write a macro level benchmark that compares the impact of async read on a system using streams. This was much more difficult. We finally settled on a Rube-Goldberg setup like this:
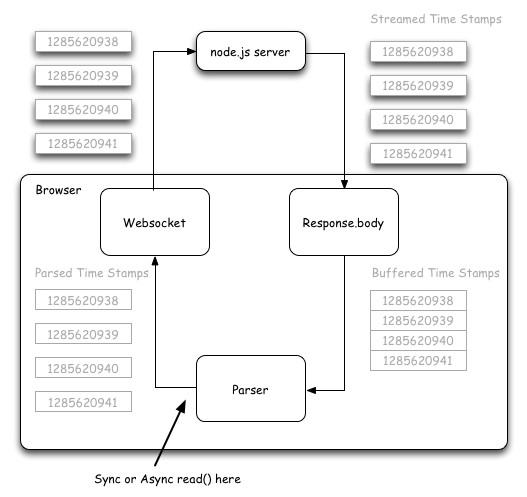
Here we have a node.js server that responds to an HTTP request by echoing back time stamps in a stream. The browser receives these time stamps using the Fetch Response body stream that has been implemented by Chrome. The time stamps are then individually parsed out and sent back to the node.js server via websocket. The node.js server then compares the time stamps to determine round-trip latency. The total numbers of time stamps are also counted to measure throughput.
The key part of this setup is where the Response body stream provides a buffered chunk of data containing multiple time stamps. A wrapper stream is used to parse the chunk into individual time stamps. Each time stamp is represented as an object. This means that a single chunk from the network-oriented Response body is translated into many smaller chunks. This is similar to the “buffer chunks in a pipe scenario” in the micro benchmark. These smaller chunks are then read using either a sync or async interface.
Switching between these read interfaces at this point gives us the difference we are looking for and lets us compare the impact of sync vs async read on the system.
The code for the macro benchmark is available on Github. You can also run the macro benchmark yourself by checking out the repo and running the node.js server on your local network.
It should be noted, however, this benchmark is not particularly stable. Since the Chrome Fetch Response body stream does not currently support backpressure, the test had to manually implement this in the node.js server to avoid simply swamping the browser. This manual backpressure mechanism then creates a possibility for deadlock with the buffering algorithm within the Response body stream. Its a bit fragile and I did not take the time to fully fix it. In the interests of time I instead restarted the test when this occurred.
For this test we did not vary any settings. Instead we simply measured the throughput across 20 executions and took the mean.
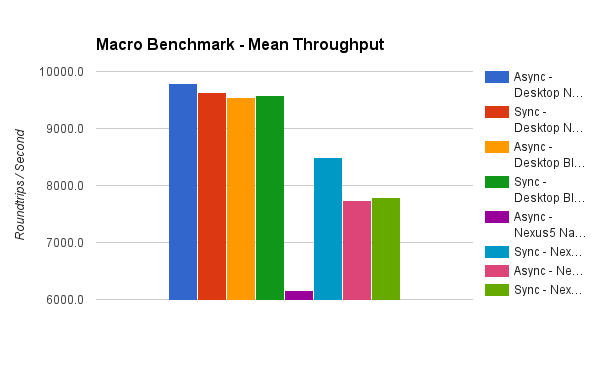
We can see a few things here. First, the Nexus5 achieves about 80% of the throughput of desktop. The main exception is the async read case using native promises which runs much slower. This particular result is not too surprising, however, given the native-vs-Bluebird results above.
Again, since we expect native promises to approach Bluebird performance in the future, we will just ignore the native promise results for now.
For the Bluebird cases it appears that there is not much difference between async read and sync read in this test. Indeed, performing a t-test on the data shows alpha values ranging from 0.16 to 0.82. This suggests that there is not enough statistical evidence to detect a difference between async and sync read.
The data for all of these results can be found in this spreadsheet.
Conclusions
The results from the micro benchmark clearly show that in isolation a synchronous read function is faster than an asynchronous read function for a particular kind of buffered work load. The macro benchmark, however, supports Domenic’s contention that this type of work load does not realistically occur in systems performing I/O.
Benchmarking is hard. It’s especially hard when you’re trying to compare non-existent, potential implementations of a specification. The tests we ran are clearly not perfect here, but they are reasonable approximations of future behavior and do provide some insight. In the absence of better data we must decide how to move forward with the information at hand.
Given these results, we have concluded that the asynchronous read function in the Streams API is acceptable and will likely not be a performance problem.
Thank you to Domenic Denicola for reviewing an earlier draft of this post.