Patching Resources in Service Workers
Consider a web site that uses a service worker to provide offline access. It consists of numerous resources stored in a versioned Cache.
What does this site need to do when its code changes?
It clearly needs to update its cache. Thanks to the service worker life cycle,
this is relatively straightforward. As described in Jake Archibald’s
Offline Cookbook, the site simply needs to cache.addAll() the new resource
in the install event and caches.delete() the old Cache in the activate event:
self.addEventListener('install', function(evt) {
evt.waitUntil(
caches.open('v2').then(function(cache) {
return cache.addAll(resourceList);
})
);
});
self.addEventListener('activate', function(evt) {
evt.waitUntil(caches.delete('v1'));
});
This is nice and simple, but it does have one downside. It requests the entire resource list from the browser’s network stack on each upgrade.
This can be mitigated pretty easily For unchanged files. Simply set the correct
cache control headers on the server so you hit the HTTP cache. Or even copy the
resource directly from the old v1 cache to the new v2 cache.
That being said, we normally only update when things change. Is there anything we can do to improve the situation for modified resources?
Can we do better?
Consider this demo site (source code). Open it with your devtools network panel visible. It should work in both Firefox and Chrome release channels. (There is an issue with Chrome on windows, though.)
The buttons let you simulate upgrading a cache as the service worker would. Each version of the cache stores two resources; JQuery and Bootstrap. The contents of each resource is shown in a separate div so you can inspect the final loaded resource.
So, to model the typical upgrade process you would click:
- Load v1 Resources
- Clear All Resources
- Load v2 Resources
- Clear All REsources
- Load v3 Resources
This creates the following network traffic.
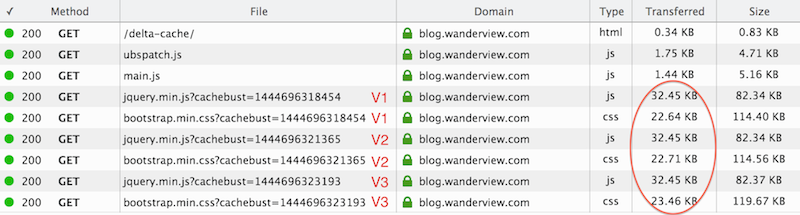
However, if you click the load buttons in sequence without clearing, then we can see an optimization at work. So:
- Load v1 Resources
- Load v2 Resources
- Load v3 Resources
Which gives us:
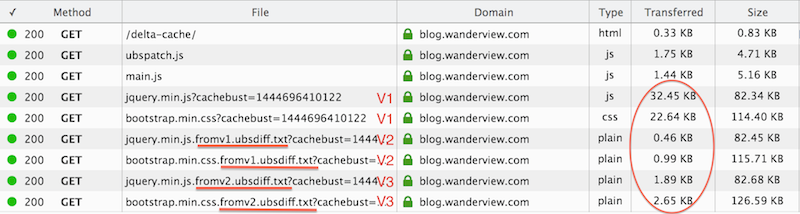
In this case the v2 and v3 network traffic has been reduced by a factor of ten.
What is going on here?
The demo site is using an optimization called delta encoding to request only the changes in each resource. In this (admittedly contrived) case, both JQuery and Bootstrap are only being updated across minor versions, so the changes are quite small.
While the demo is using relatively small updates, delta encoding is still useful for larger changes. For example, sending the gzip’ed differences between JQuery 1.11.3 and 2.1.4 still only requires 8.6KB.
Of course, delta encoding is not a new concept. We use it every day with git and other tools. It was even proposed as an HTTP standard in 2002 in RFC 3229. It never caught on, however, because it requires extensive server resources to implement in a general way. For example, see this article on the CloudFlare blog.
The nice thing about service workers is they let us implement this algorithm in a site-specific way that is tailored to our use case. We determine where it makes sense to use delta encoding and skip it for resources where its not feasible. This lets us use the optimization without dealing with the complications of making it general purpose across all web sites.
Diff’ing and Patching
When I first considered delta encoding, I searched for a good diff/patch algorithm implemented in javascript. At the time I didn’t find much that was suitable. It seemed most libraries were either focused on creating traditional UNIX diff output or wrappers around native code. I needed a patching algorithm solely implemented in javascript, however.
In order for delta encoding to be useful the patching algorithm in the browser must be small. We can’t just use emscripten to compile a C patch program, because the size of the resulting library would dwarf any advantage gained from the delta encoding.
(It occurrs to me now that the projects like js-git might have patching code I could have borrowed, but I didn’t think of it at the time.)
In the end I adapted Colin Percival’s excellent set of bsdiff tools.
At first glance, bsdiff seemed like a good fit. Its an extremely effective diffing tool that works well on both text and binary resources. Whats more, bspatch is a single small C file that I could transcribe to javascript.
Then I ran into bzip. It turns out bsdiff works by creating file segments slightly larger than the original file, but with a large number of zeros for unchanged content. It then internally uses bzip to compress these segments. The result is a compact difference file.
Porting bzip seemed like a daunting task and likely to require a large library.
It occurred to me, however, the browser already knows how to decompress gzip natively. Could we instead strip the internal bzip compression out and just serve the resulting files with gzip encoding?
The answer is yes. The demo site uses exactly this technique.
In fact, if you look closely at the delta encoding network traffic, you will see devtools reports the resulting uncompressed file as being slightly larger than the original resource. This is bsdiff’s internal segment algorithm at work.
The u(ncompressed) bsdiff code is on github as ubsdiff. In addition, I’ve published ubspatch as a separate npm module. Currently the ubsdiff code is only available in C, but it could also be ported to javascript.
Should I Use This in Production
Probably not with this specific code. I wrote a lot of it while my kids were throwing legos at my head.
The technique, however, seems suitable for service worker updates using the install event. The install event runs in parallel with any currently active service worker, so you will not create problems for the current page.
For read-through-caching, though, its less clear. In these cases you will often need to patch the resource on-demand in a fetch event handler. This is problematic because the patching can take a non-trivial amount of time. Since its not streaming yet, it will just block the worker event loop while it runs. If there are additional fetch events waiting to be serviced, this will cause network jank.
Ideally, service workers would allow heavy workloads like patching to be offloaded via a worker. The spec really needs to be extended to allow workers to be accessed within the service worker.
(You could bounce a postMessage() through the fetch event source document to
a worker that does the patching and then back, but that seems a bit convoluted
to really recommend.)
Frameworks and Tools
Ultimately I think this technique probably needs client-side frameworks and server-side tooling to really shine.
A framework could transparently handle a number of things:
- Automatically include currently cached resource versions in outgoing requests.
- Dynamically determine if using delta encoding makes sense for any given resource.
- Automatically patch differences returned from the server.
- Provide integrity checks on the final resource after patching. This is a crucial step for any production system, but not something I included in the prototype here.
Service Workers Are Delightful
At the end of the day, though, I find service workers exciting because they let web developers implement features that had previously been the sole domain of the browser. The browsers are old, creaky, and have lots of constraints. Web sites can break free of these constraints by using service workers.